在 Inflection,我们的使命是为每个人打造个性化的人工智能。去年 5 月,我们发布了Pi — 一款个性化人工智能,旨在具有同理心、乐于助人且安全。11 月,我们宣布了一个新的主要基础模型Inflection-2,这是当时全球第二好的LLM。

现在我们正在将 IQ 添加到 Pi 的卓越 EQ 中。
我们正在推出 Inflection-2.5,这是我们升级的内部模型,可与 GPT-4 和 Gemini 等全球领先的 LLM 相媲美。它将原始能力与我们标志性的个性和独特的共情微调结合在一起。Inflection-2.5 现已在pi.ai、iOS、Android或我们的新桌面应用程序上向所有 Pi 用户开放。
我们以令人难以置信的效率实现了这一里程碑:Inflection-2.5 接近 GPT-4 的性能,但仅使用 40% 的计算量进行训练。
我们在编码和数学等智商领域取得了特别的进步。这转化为关键行业基准的具体改进,确保 Pi 始终走在技术前沿。Pi 现在还整合了世界一流的实时网络搜索功能,以确保用户获得高质量的突发新闻和最新信息。
我们已经向用户推出了 Inflection-2.5,他们非常喜欢 Pi!我们已经看到它对用户情绪、参与度和留存率产生了非常显著的影响,加速了我们的有机用户增长。
我们每天有 100 万活跃用户,每月有 600 万活跃用户,现在已经与 Pi 交换了超过 40 亿条消息。
与 Pi 的一次平均对话持续33 分钟,其中十分之一的人每天对话持续超过一小时。每周与 Pi 交谈的人中,约有60%的人会在下一周再次与 Pi 交谈,而且我们发现每月的粘性比领先的竞争对手更高。

借助 Inflection-2.5 的强大功能,用户可以与 Pi 讨论比以往更广泛的话题:讨论时事、获取当地餐馆推荐、备考生物考试、起草商业计划、编写代码、准备重要对话,或者只是讨论爱好。我们迫不及待地想向您展示 Pi 的功能。
技术结果

下面,我们展示了一系列关键行业基准的结果。为简单起见,我们将 Inflection-2.5 与 GPT-4 进行比较。这些结果显示了 Pi 现在如何整合与公认的行业领导者相当的 IQ 功能。由于报告格式不同,我们会仔细注意用于评估的格式。
Inflection-1 使用的训练 FLOP 约为 GPT-4 的 4%,在各种面向 IQ 的任务中,其平均性能约为 GPT-4 的 72%。目前为 Pi 提供支持的 Inflection-2.5 尽管仅使用了 40% 的训练 FLOP,但其平均性能却达到了 GPT-4 的 94% 以上。我们看到整体性能有了显著提升,其中最大的提升来自 STEM 领域。
Inflection-2.5 在 MMLU 基准测试中比 Inflection-1 有显著提升,MMLU 基准测试是一项多样化的基准测试,用于衡量从高中到专业级难度的广泛任务的表现。我们还对 GPQA Diamond 基准测试进行了评估,这是一个极其困难的专家级基准测试。

我们还包括两项不同的 STEM 考试的结果:匈牙利数学考试以及物理 GRE(物理学研究生入学考试)的成绩。
对于匈牙利数学,我们使用此处提供的少样本提示和格式,以便于重现。Inflection-2.5 仅使用提示中的第一个示例。
我们还发布了已发布的物理 GRE 考试(GR8677、GR9277、GR9677、GR0177)的处理版本,并将 Inflection 2.5 与 GPT-4 在第一轮考试中的表现进行了比较。我们发现 Inflection-2.5 在 maj@8 中的表现处于人类考生的 85% 左右,在 maj@32 中几乎达到最高分。我们在下面的结果中排除了一些带有图像的问题,以便进行更广泛的比较。尽管如此,我们还是发布了所有问题。

在 BIG-Bench-Hard(BIG-Bench 问题的一个子集,对于大型语言模型来说很难)上,Inflection-2.5 比 Inflection-1 提高了 10% 以上,并且可以与最强大的模型相媲美。
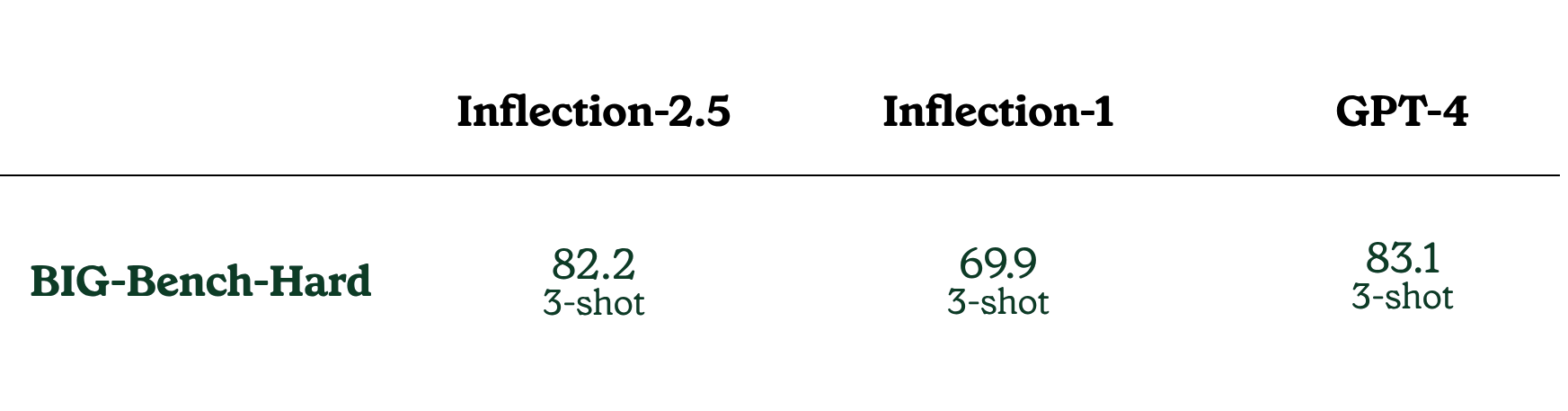
我们还在MT-Bench上评估了我们的模型,这是一个广泛使用的社区排行榜,用于比较模型。然而,在评估 MT-Bench 之后,我们发现推理、数学和编码类别中的大部分示例(近 25%)的参考解决方案不正确或前提有缺陷。因此,我们更正了这些示例并在此处发布了该版本的数据集。
在评估两个子集时,我们发现在适当修正的版本中,我们的模型更符合我们基于其他基准的预期。

Inflection-2.5 在数学和编码性能方面较 Inflection-1 有显著改进,如下表所示。

在 MBPP+ 和 HumanEval+ 这两个编码基准上,我们看到了比 Inflection-1 有了巨大的改进。
对于 MBPP,我们报告了DeepSeek Coder中 GPT-4 的值。对于 HumanEval,我们获取了EvalPlus排行榜(GPT-4,5 月 23 日)中的结果。

我们还根据 HellaSwag 和 ARC-C 评估了 Inflection-2.5,这是各种模型报告的常识和科学基准。在这两种情况下,我们都看到了这些饱和基准的强劲表现。

以上所有评估均使用现在为 Pi 提供支持的模型完成,但我们注意到,由于网络检索的影响(上述基准均未使用网络检索)、少量提示的结构和其他生产方面的差异,用户体验可能会略有不同。
简而言之,Inflection-2.5 保留了 Pi 独特、平易近人的个性和非凡的安全标准,同时成为了全面更有用的模型。
文章出自 inflection官网